
Развитие системы здравоохранения в России зависит от использования современных технологий. Все большее внимание уделяется применению различных математических алгоритмов для повышения качества медицинской помощи [1, 2]. Одним из направлений применения искусственного интеллекта (ИИ) является машинное обучение (МО). Основная задача МО заключается в создании алгоритмов, которые могут принимать входные данные и использовать их для прогнозирования выходной информации по мере появления новых данных. Стоит отметить, что МО представляет собой не только статистические методы, и в основе МО лежит построение алгоритмов, основанных на обучении, без явной формы решения [3].
МО широко применяется в различных сферах медицины, в том числе внедряется и в области вспомогательных репродуктивных технологий (ВРТ). В репродуктивной медицине развитие МО привело к созданию большого количества вспомогательных программных продуктов [4]. В настоящий момент внимание ученых привлекает разработка программ для прогнозирования эффективности ВРТ, а также выбора и оптимизации метода лечения [5].
Стоит отметить, что ошибочное и неточное прогнозирование исхода программы ВРТ не позволяет своевременно ориентировать супружескую пару на использование того или иного метода лечения и корректировать ожидания пациентов в отношении частоты наступления беременности, а также препятствует целесообразному клинико-экономическому распределению средств Фонда обязательного медицинского страхования (ОМС) [6]. В связи с этим при разработке программного продукта задача прогнозирования эффективности программы ВРТ становится наиболее приоритетной.
Прогнозирование результативности программы ВРТ при помощи МО может быть осуществлено с использованием различных алгоритмов в зависимости от типа данных и поставленной задачи. Среди основных методов МО, используемых в репродуктивной медицине, выделяют логистическую регрессию, алгоритм решающего дерева, метод случайного леса (Random Forest) [7].
Логистическая регрессия
Логистическая регрессия решает задачу классификации, показывая вероятность того, что данное исходное значение принадлежит к определенному классу. Если точки исходных данных удовлетворяют этому требованию, то их можно назвать линейно разделяемыми [8] (рис. 1).
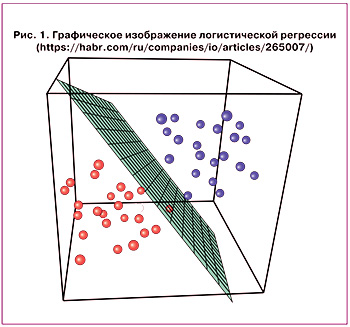
При этом, чем дальше находится точка от разделяющей поверхности, тем выше шансы, что она принадлежит к данному классу.
Алгоритм решающего дерева
Алгоритм решающего дерева разделяет набор данных на меньшие подмножества в зависимости от их характеристик. Суть метода заключается в том, что дерево решений многократно разделяет данные, пока не останется только один класс. При построении дерева решений используется критерий Джини (Gini impurity) [9].
При выборе разделения узла по определенному признаку, критерий Джини отражает, насколько это разделение снижает неопределенность в данных [10].
Алгоритм случайного леса (Random Forest)
Стоит отметить, что одно решающее дерево имеет тенденцию к переобучению под конкретную обучающую выборку, поэтому на практике следует использовать композицию решающих деревьев (Random Forest). В основе алгоритма Random Forest лежит использование нескольких решающих деревьев. Они показывают логику, благодаря которой исследователь принимает решения. Оптимизация решающих деревьев под конкретную задачу сводится к перебору признаков и порогов разбиения, чтобы найти лучшее разбиение. Дерево сильно меняется при изменении выборки, поэтому для построения разнообразных деревьев из выборки длиной M выбираются подмножества такой же длины M с возвращением, и на этих подмножествах строятся деревья. Такой подход называется bootstrap. В задаче регрессии результаты, полученные «множеством» деревьев, усредняются, в задаче классификации – принимается решение голосованием по большинству. Также при построении дерева можно перебирать не все признаки, а выбирать из некоторого случайного подмножества q. Деревья можно строить параллельно, так как построения не зависят друг от друга [11].
В настоящий момент опубликовано большое количество работ, посвященных разработке предиктивной модели исхода программы ВРТ на основе МО; однако исследования, посвященные сравнению разных алгоритмов МО и изучению работы каждой модели в зависимости от полученных результатов, представлены в современной литературе в ограниченном объеме в связи с техническими ограничениями, такими как трудности в определении причинно-следственных связей между данными, полученными в ходе МО, необходимости использования большого массива данных, построении модели с использованием различных алгоритмов и т.д.
Целью данной работы явилось сравнение прогностической способности логистической регрессии, алгоритма решающего дерева и Random Forest в отношении частоты наступления беременности на основании клинико-анамнестических и эмбриологических данных когорты пациентов при лечении бесплодия методами ВРТ.
Материалы и методы
Совместно со специалистами в области МО и ИИ на первом этапе работы было проведено исследование по построению алгоритма решающего дерева для определения наиболее значимых предикторов наступления клинической беременности в программе ВРТ [12]. Среди данных факторов максимальный вклад в частоту наступления беременности внесли следующие параметры: наличие/отсутствие беременностей в анамнезе, параметры стимулированного цикла (количество ооцит-кумулюсных комплексов (ОКК), ооцитов MII, зигот), показатели спермограммы в день пункции, количество эмбрионов отличного и хорошего качества, а также качество эмбриона (размер эмбриона, состояние внутренней клеточной массы и клеток трофэктодермы).
Дерево было построено путем разбиения данных на подмножества на основе значений признаков с целью классификации с использованием системы Python с определением устойчивости данных и проверкой полученных данных на тестовой выборке с использованием библиотеки Scikit-learn. При построении дерева решений был использован критерий Джини (Gini impurity). Этот критерий измеряет неопределенность или «чистоту» множества элементов путем оценки вероятности неправильной классификации случайно выбранного элемента из множества [12].
В данном исследовании была проанализирована точность моделей, построенная при помощи алгоритма решающего дерева, логистической регрессии и Random Forest. Ретроспективно в исследование были включены 854 супружеские пары в возрасте от 21 до 44 лет, обратившиеся за лечением бесплодия методом ВРТ. От каждой пары было получено письменное добровольное информированное согласие на обработку персональных данных.
Критерии включения в исследование: бесплодие, обусловленное трубно-перитонеальным, мужским или сочетанным фактором, хронической ановуляцией или сниженным овариальным резервом, а также наличие нормального кариотипа супругов, овариальная стимуляция по протоколу с антагонистом гонадотропин-рилизинг-гормона (антГнРГ), стандартный протокол поддержки посттрансферного периода, получение собственных ооцитов в день трансвагинальной пункции (ТВП), перенос 1 эмбриона.
Критерии исключения: аномалии строения матки, аномалии кариотипа, использование донорских ооцитов или спермы.
Все пациентки, включенные в исследование, были распределены на 5 групп в зависимости от возраста: 1-я группа (n=100) – 21–24 года, 2-я группа (n=195) – 25–29 лет, 3-я группа (n=220) – 30–34 года, 4-я группа (n=256) – 35–39 лет, 5-я группа (n=83) – 40–44 года.
Пациенткам, включенным в исследование, была проведена овариальная стимуляция по протоколу с антГнРГ со 2-го или 3-го дня менструального цикла. По достижении диаметра фолликулов ≥17 мм пациенткам был назначен триггер финального созревания ооцитов – препарат хорионического гонадотропина человека (ХГЧ) (n=600), или в случае риска возникновения синдрома гиперстимуляции яичников производилась замена триггера на агонист ГнРГ (n=171), или был назначен двойной триггер финального созревания ооцитов (n=83). Через 35–36 ч после введения триггера овуляции была проведена ТВП с последующим забором ооцитов и оценкой их качества. Оплодотворение полученных ооцитов было выполнено методом экстракорпорального оплодотворения (ЭКО) в 5,6%, интрацитоплазматической инъекции сперматозоида в ооцит (ИКСИ) – в 81,9% и физиологического ИКСИ (ПИКСИ) – в 12,5% случаев. Все этапы культивирования проводили в мультигазовых инкубаторах СООК (Ирландия) в каплях по 25 мкл под маслом (Irvine Sc., USA) на базе отделения вспомогательных технологий в лечении бесплодия им. проф. Б.В. Леонова. На 5-е сутки после оплодотворения осуществлялся перенос эмбриона в полость матки с помощью мягкого катетера Wаllасe (Германия) или Сооk (Австралия). Оставшиеся эмбрионы, подходящие по качеству для дальнейшего применения в криопротоколе, криоконсервировали. Поддержка лютеиновой фазы и дальнейшее ведение посттрансферного периода осуществлялись по стандартной общепринятой методике. На 14-й день после переноса эмбрионов производилась оценка уровня бета-субъединицы ХГЧ (β-ΧГЧ). При положительном результате β-ΧГЧ через 21 день после переноса пациенткам выполнялось ультразвуковое исследование малого таза для диагностики клинической беременности. Дальнейшее ведение беременности осуществлялось индивидуально.
В исследовании также проанализированы эмбриологические параметры стимулированного цикла: показатели спермограммы в день ТВП (концентрация сперматозоидов, процент прогрессивно-подвижных сперматозоидов, процент непрогрессивных сперматозоидов, неподвижных, процент морфологически здоровых сперматозоидов), количество ОКК, зрелых ооцитов MII, количество оплодотворившихся ооцитов (зиготы), качество эмбриона (размер эмбриона, состояние внутренней клеточной массы и клеток трофэктодермы), количество бластоцист отличного, хорошего и среднего качества, а также количество эмбрионов, остановившихся в развитии на 2–3-и сутки после оплодотворения. Кроме этого, была проанализирована частота наступления клинической беременности.
Статистическая обработка данных и алгоритм построения моделей МО
В исследовании проанализирован 51 определенный входной признак, их разбили на 3 группы:
- бинарные – дискретные переменные, принимающие только два значения (например, количество программ ЭКО в анамнезе);
- категориальные – дискретные переменные, принимающие одно из конечного количества значений и обозначающие принадлежность объекта к какой-то категории (например, качество эмбриона по морфологическим критериям оценки);
- вещественные – значения признака из вещественного множества (например, концентрация сперматозоидов в эякуляте).
Для бинарных признаков была произведена замена значений на {0, 1}. Для модели логистической регрессии все вещественные признаки были нормированы, а категориальные признаки кодированы с помощью технологии One-Hot Encoding: для кодируемого категориального признака создано N новых признаков, где N – число категорий. Каждый i-й новый признак – бинарный характеристический признак i-й категории [13]. One-Hot Encoding представляет собой один из методов преобразования данных для подготовки их к алгоритму и получения лучшего прогноза. С помощью One-Hot Encoding происходит конвертация каждого категориального значения в новый категориальный столбец и присваивается этим столбцам двоичное значение 1 или 0. Для моделей логистической регрессии, решающего дерева и случайного леса все категориальные признаки были также кодированы с помощью One-Hot Encoding.
Распределение целевой переменной (клиническая беременность) среди всех участников данного исследования представлено на рисунке 2.
«ДА (клиническая беременность +)» – 435 записей.
«НЕТ (клиническая беременность -)» – 419 записей.
Перед этапом моделирования анализируемая выборка была разделена случайным образом на обучающую и тестовую в отношении train – 70%, test – 30%.
Для моделирования были рассмотрены следующие алгоритмы.
- Логистическая регрессия.
- Решающее дерево.
- Random Forest.
Для проведения анализа метрик качества модели были введены критерии precision и recall. Precision можно интерпретировать как долю объектов, названных классификатором положительными и при этом действительно являющихся положительными, а recall показывает, какую долю объектов положительного класса из всех объектов положительного класса нашел алгоритм.
Результаты
Для сравнения эффективности каждой модели были использованы метрики качества, отраженные в таблице.
Согласно таблице и результатам анализа метрик качества, лучшие результаты демонстрирует модель Random Forest.
Для интерпретации важности каждого показателя в итоговом прогнозе модели была использована библиотека SHAP (SHapley Additive exPlanations), представленная на рисунке 3. Для оценки важности показателей были рассчитаны значения Шэпли, которые позволяют выявлять все возможные комбинации и варианты, а проанализировав данные, определить, какие факторы на самом деле важны при выборе. Для оценки важности показателя была выполнена оценка предсказаний модели «с» и «без» данного показателя.
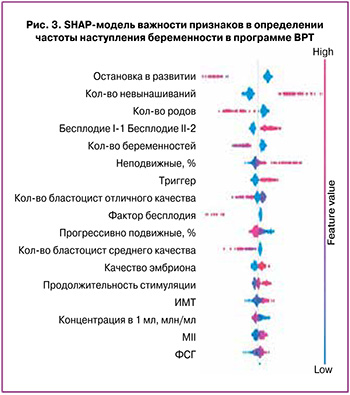
Для правильного анализа графика необходимо отметить, что каждая точка является отдельным наблюдением и чем выше признак по оси Y, тем он более важен в отношении частоты наступления беременности (рис. 3). Значения слева от центральной вертикальной линии – это negative класс (0), справа – positive (1); при этом, чем толще линия на графике, тем больше таких точек наблюдения. Цветом обозначены значения соответствующего признака: чем выше признак – тем более красным цветом он обозначен, низкие – синим.
Таким образом, полученная модель определила «дополнительные» значимые факторы, имеющие важное значение в определении эффективности программы ВРТ: остановка эмбрионов в развитии, триггер финального созревания ооцитов, количество эмбрионов отличного и среднего качества, продолжительность стимуляции, фактор бесплодия, индекс массы тела, уровень ФСГ и АМГ. Кроме этого, значимость предикторов, которые были определены на предыдущих этапах работы, при помощи алгоритма решающего дерева была также подтверждена при помощи Random Forest: наличие/отсутствие беременностей в анамнезе, параметры стимулированного цикла (число ооцитов MII), показатели спермограммы в день пункции, количество эмбрионов отличного и хорошего качества, а также качество эмбриона согласно морфологическим критериям оценки (размер эмбриона, состояние внутренней клеточной массы и клеток трофэктодермы).
Обсуждение
Алгоритмы автоматического обучения постепенно становятся неотъемлемой частью современной науки [14].
В данном исследовании были проанализированы три алгоритма МО: логистическая регрессия, дерево решений и Random Forest. Одни из наиболее эффективных моделей на текущий момент для решения задач классификации основаны на использовании алгоритма Random Forest. На их долю приходится более 70% всех разработанных моделей. Random Forest служит одним из наиболее распространенных подходов для решения задач классификации и представляет собой композиционный метод, который формирует набор различных моделей классификации для достижения лучшей точности. Базовый же алгоритм по классификации, с которым всегда происходит сравнение всех разрабатываемых моделей, – это логистическая регрессия. Ее особенностями являются простота реализации, скорость работы, а также интерпретируемость результатов (логистическая регрессия оценивает вероятность наступления события и интерпретирует результаты на основе важности каждого признака). Учитывая, что полученные метрики качества precision и recall были максимальными у модели Random Forest, то в ходе анализа была выбрана реализация именно этого алгоритма.
Еще один широко распространенный алгоритм МО – искусственные нейронные сети. Тем не менее, исходя из объема обучающего датасета и типа собранных данных, использование нейронных сетей в данном случае нецелесообразно, так как для построения качественной модели с использованием нейронных сетей необходим больший объем выборки. В связи с этим для решения задачи классификации признаков с использованием данного объема входных параметров предложены три наиболее подходящие и оптимальные под решение данной задачи модели [15].
Логистическая регрессия – метод построения линейного классификатора, позволяющий оценивать вероятности принадлежности объектов классам. Логистическая регрессия использует линейную комбинацию входных признаков и соответствующих весов, которая описывает линейную гиперплоскость в пространстве признаков. Затем этот результат проходит через логистическую функцию, которая переводит линейную комбинацию в вероятность принадлежности объекта к одному из классов [8].
Преимущества
1. Это относительно простой алгоритм, который требует небольшого количества вычислительных ресурсов.
2. Интерпретируемость: логистическая регрессия позволяет понимать, какие переменные влияют на классификацию и каким образом.
3. Позволяет получать высокую точность модели с использованием небольших наборов данных.
Недостатки
1. Требует нормализации признаков, чтобы гарантировать, что признаки вносят одинаковый вклад в модель.
2. При решении задач с большим количеством признаков или сложной структурой данных точность получаемой модели снижается.
3. Может показывать низкую точность, если классы не являются линейно разделимыми.
Данный алгоритм был интересен в первую очередь из-за возможности интерпретации результатов, а также проверки гипотезы о линейной разделимости классов; однако на практике он показал низкое качество, что подтверждает более сложную структуру в данных для обучения. Использовалась реализация модели для Python из библиотеки scikit-learn (https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html).
Стоит отметить, что дерево решений представляет собой иерархическую древовидную структуру и помогает в решении задач по классификации и регрессии. В отличие от нейронных сетей, дерево решений как аналитическая модель проще, потому что правила генерируются за счет обобщения обучающих примеров, описывающих предметную область. Малые изменения в данных могут привести к существенным изменениям в структуре дерева, что делает модель неустойчивой.
Универсальным алгоритмом МО может выступать модель Random Forest, суть которой состоит в использовании ансамбля решающих деревьев. Само по себе решающее дерево предоставляет крайне невысокое качество классификации, но из-за большого их количества результат значительно улучшается [9].
Полученные результаты показали, что максимальные значения precision и recall были получены для модели с использованием алгоритма Random Forest. Модель, построенная c использованием Random Forest, показала, что максимальное влияние на эффективность программы ЭКО оказывает наличие/отсутствие беременности в анамнезе/количество невынашиваний/родов, а также качество эмбриона и количество эмбрионов, остановившихся в развитии на 2–3-и сутки после оплодотворения. Кроме этого, на частоту наступления беременности оказывают влияние триггер финального созревания ооцитов, продолжительность стимуляции, количество бластоцист среднего и отличного качества, показатели спермограммы в день пункции, а также количество ооцитов МII.
В исследовании, опубликованном в 2022 г., была построена модель, прогнозирующая частоту наступления беременности при помощи МО. В исследование были включены 24 730 супружеские пары, проходящие лечение бесплодия методом ЭКО/ИКСИ. Обучение алгоритма производилось при помощи модели Random Forest и логистической регрессии. В исследовании были определены переменные, в максимальной степени влияющие на прогноз лечения, среди которых наиболее значительный вклад внес протокол овариальной стимуляции, а в качестве метода МО наиболее перспективным зарекомендовал себя Random Forest [16].
Полученные результаты согласуются с данными других коллег, которые обнаружили, что фактор бесплодия и показатели эякулята в день ТВП также следует включать в модель для расчета вероятности наступления беременности. Согласно исследованию Vaegter K.K. et al., среди наиболее информативных показателей оценки качества эякулята следует выделить концентрацию сперматозоидов, подвижность и объем материала. Стоит отметить, что перспективными представляются исследования по определению наиболее значимого показателя оценки качества эякулята для оптимизации подготовки мужчины к программе ВРТ и оценки эффективности проводимого лечения [17].
Наличие/отсутствие беременностей в анамнезе выступает еще одним значимым предиктором наступления беременности в программе ВРТ согласно построенным прогностическим моделям. Согласно исследованию Tarín J.J. et al., фактор бесплодия, наличие/отсутствие беременности в анамнезе, а также возраст пациентки являются определяющими факторами наступления беременности в программе ВРТ. Стоит подчеркнуть, что в данном исследовании возраст супружеской пары не показал значимого влияния на частоту наступления беременности в программе ВРТ, возможно, в связи с тем, что при помощи проведения МО были обнаружены наиболее значимые определяющие факторы, которые напрямую зависят от возраста [18].
По сравнению с логистической регрессией алгоритмы МО являются более чувствительными и более точными методами проверки, для которых ограничения традиционной регрессии применимы в меньшей степени. В репродуктивной медицине алгоритмы МО широко используются для определения наиболее значимых предиктивных маркеров наступления беременности в программе ВРТ. Yang H. et al. проанализировали факторы, влияющие на частоту наступления беременности в программе ЭКО с последующим построением прогностической модели. В исследование «случай-контроль» были включены данные 369 женщин, проходящих лечение бесплодия методом ВРТ. Для выявления потенциальных предикторов был проведен одномерный и многомерный анализ логистической регрессии и модели Random Forest. Важность переменных была показана в соответствии со средним снижением критерия Джини. Согласно полученным данным, максимальный вклад в эффективность программы ВРТ вносят возраст, индекс массы тела, количество попыток ЭКО в анамнезе, гематокрит, уровень ЛГ, прогестерона, толщина эндометрия, уровень ФСГ. Полученные результаты позволяют выявлять группы пациентов с высоким риском негативных исходов лечения в программе ВРТ и своевременно обеспечить адекватную подготовку и лечение [19].
Таким образом, полученные результаты отражают необходимость дальнейшего изучения влияния определенных факторов на частоту наступления беременности. Построение более точных прогностических систем с использованием большего объема выборки, а также дополнительных математических подходов позволит не только повысить частоту наступления беременности за счет оптимизации корригируемых факторов, но и определить максимально перспективную группу пациентов для целесообразного распределения бюджета ОМС на финансирование программ ЭКО. Стоит отметить, что перспективным представляется анализ полученной выборки с использованием алгоритма градиентного бустинга, который в значительной степени может нивелировать недостатки работы модели Random Forest и обеспечивает более точные результаты. Кроме этого, использование в математической модели уникальных неинвазивных биомаркеров оценки качества эмбриона при помощи анализа среды культивирования бластоцисты позволяет повысить прогностическую точность алгоритма [20]. В рамках данного исследования было собрано более 500 образцов фолликулярной жидкости, семенной плазмы, сперматозоидов и среды культивирования эмбриона у пациентов, проходящих лечение бесплодия методом ВРТ, согласно интегрированной системе хранения биологических образцов [21].
Заключение
На сегодняшний день точность моделей на основе регрессионного анализа не превышает 70%. Для повышения точности прогнозирования эффективности программы ВРТ требуются более качественные алгоритмы с интегральным подходом к решению задачи, а также молекулярные маркеры, повышающие диагностическую точность. Расширение обучающей выборки, а также построение индивидуальных прогностических моделей с использованием более точных математических подходов позволят сократить количество потенциальных клинико-анамнестических предикторов частоты наступления беременности в программе ВРТ, что позволит создать максимально удобный и простой в использовании программный продукт. Данному вопросу будут посвящены дальнейшие научные исследования.


